
When Intelligence Becomes Free
What comes after the compute bottleneck?

👋Hey!
Welcome the third and final installment in my series on data centers! If you missed any of the previous ones feel free to check them out below!
Part 1: So You Wanna Build a Data Center
Part 2: The Silicon Clock vs. The Infra Clock
Super excited to hear your thoughts on this one!
Welcome to my 17 new subscribers since last Tuesday’s email! If you’re reading this and haven’t subscribed yet, here’s your chance! Subscribe to join the community of 58 readers receiving my weekly essay about tech, business strategy, or anything else I find interesting!

The World We Can’t Build Yet
A couple weeks ago I highlighted World Labs in my No-Creds Notes post. Their vision is to build world models that, from a simple prompt or reference photos, can construct immersive, navigable, physically consistent environments.
At a moment’s notice, you could be exploring early 20th century London, generated as far as the eye can see. Go into a nearby pub and the interior materializes just like that.
Beyond gaming and entertainment, the technology promises to further the world of robotics. Instead of gathering training data through slow, privacy-invasive teleoperation, companies could generate millions of synthetic, physics-aware scenarios to train autonomous robots.
World models aren’t alone, either. From fully automated startups to real-time generative education to self-improving agents, countless product ideas exist that could remake entire industries.
The thing is, the demand side of AI is overflowing, but the ideas can’t be built. At least not now. The compute required to power them simply doesn’t exist at the price or scale they need yet.
We’ve spent the past 2 weeks learning about the supply bottleneck. The slow buildout of data centers being constrained by permitting offices, power grids, optical networks, and what that slowdown implies for the hyperscalers.
Today we flip the equation and look at what happens when the bottleneck breaks. Eventually, the infrastructure will stop dragging its feet, supply will catch up, and the over-abundant demand for AI will enter a world of near-limitless compute.
This essay is about when intelligence becomes free.
Jevons’ Paradox For Compute
To understand how and why demand will explode, I first want to jump back to 19th century Britain.
The British Empire rode a wave of industrialization to immense power in the 1800s. But by 1863, the fuel that powered this rise, coal, was running out in Britain. Concerned by this, industrialist Sir William George Armstrong raised the alarms and publicly questioned how the exhaustion of their coal reserves may affect the country.
Economist William Stanley Jevons responded by writing a book called The Coal Question. In his book, he argued that Britain’s rise had been powered by cheap and abundant coal, and, when reduced supply begins to increase prices, it will slow the country’s growth. Most importantly, he argued that technological innovation to boost efficiency would increase consumption and further exacerbate the issue.
This has come to be known as Jevons’ Paradox. When a system is made more efficient, taking less of an input to produce its output, demand will often rise so much that consumption of the input increases.
It expands beyond coal, too. Energy costs writ large act as a sort of economic friction on the world. It’s a direct input into everything we do, whether shipping our groceries, powering our computers, or fueling our travel, everything is downstream of energy. An increase to energy costs will broadly make everything more expensive and slow down the velocity of the economy while a decrease in cost should broadly accelerate the economy, growing energy consumption with it.
Cost of compute is a similar friction cost. Energy might power the physical world, but compute powers the digital one. As data centers come online and the cost of tokens falls, new use cases like the ones described in the intro become profitable for companies to launch, leading to explosive growth in token consumption.
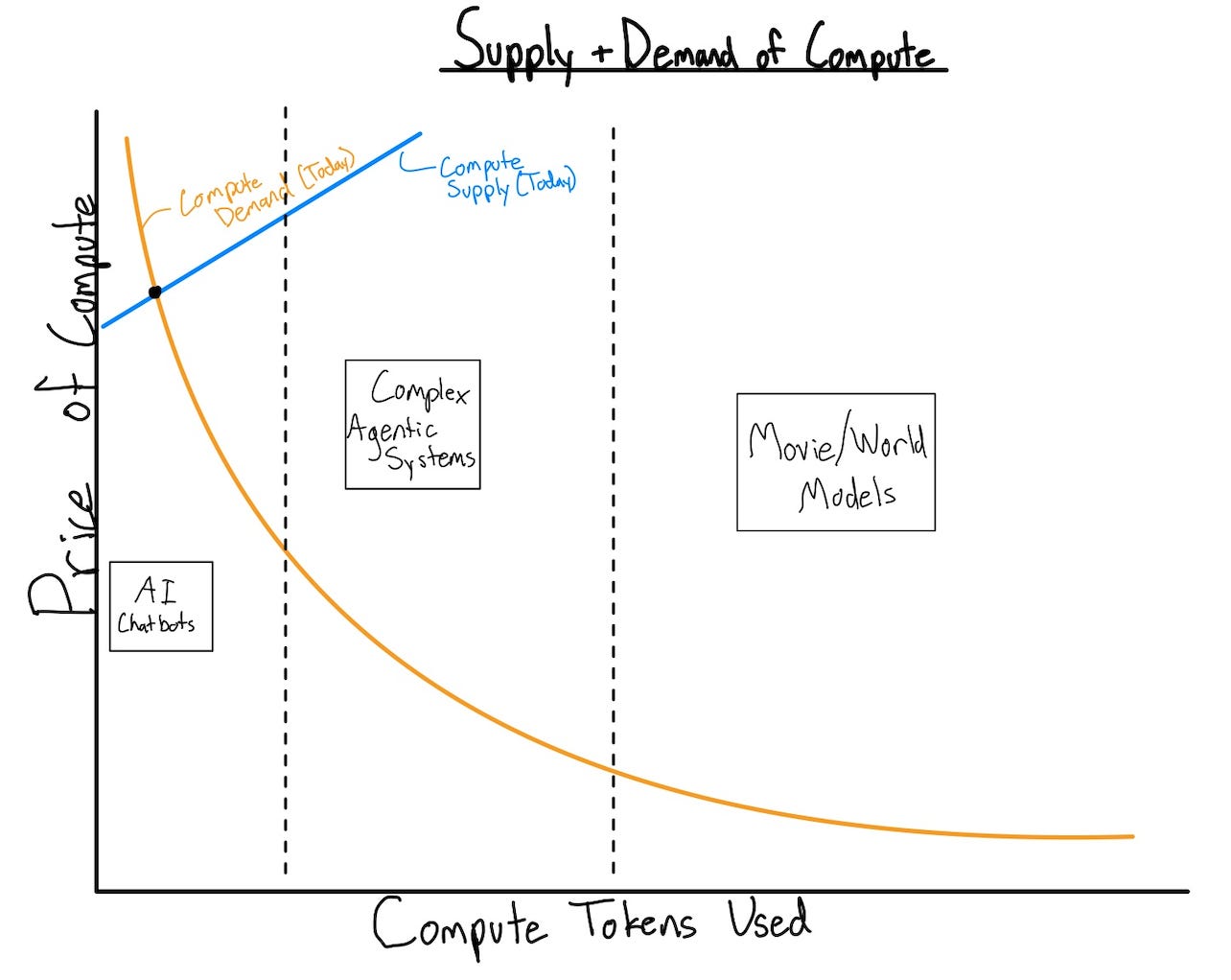
For those not versed in supply/demand graphs, the orange line in the chart above is meant to represent the compute that the public would use at any given price point and the blue line represents the size of the market’s supply of compute at any price point. Where they intersect is the price and number of tokens currently being used.
Because the data center buildout is progressing so slowly, they intersect at a high price and still only in the “chatbot” section of token consumption, beginning to press into agentic systems (realistically these sections aren’t as discrete as the chart makes them out to be). As more compute comes online, the supply curve will shift to the right, dropping price significantly and enabling more compute-hungry technologies.
Important to note here is that as the price approaches 0, the demand curve flattens out. Right now we sit at a point on the curve where an additional unit of compute coming online will drop price considerably but only marginally lift token consumption. As we approach and even pass an inflection point along that curve, even just incremental price reductions will exponentially increase consumption. Because of this, even if GPU and AI innovation slows down, growth will still explode.
Now, I do want to qualify this with the fact that we are still early. I did some research into what it would cost to produce one 30-minute TV show using AI and, at first, was surprised to see answers in the range of $5k to $15k! Why aren’t more people doing this already?!
Well, that might be the cost to produce 30 minutes of video with at least a loosely cohesive story, but the compute required to write a compelling story with consistent characters and setting can’t be quantified because that much compute isn’t publicly available yet.
While the technology may not be available yet, many see the writing on the wall. For the second straight year, Coke’s annual holiday commercial was entirely AI-generated and Disney just announced their plans to introduce AI-generated short form video to Disney+, allowing users to create and share clips featuring their IP.
So why are companies investing in this if it doesn’t make sense yet? While we’re still probably a couple years away from larger, more compute-intensive projects becoming feasible, progress will happen so fast that it feels like a switch was flipped overnight and anyone who’s not prepared will be left in the dust.
The Bottleneck Breakthrough
This may be counterintuitive after spending the last couple posts explaining all the issues with the data center buildout, but compute will break out of its bottleneck. Google has come out and said they aim to double compute capacity every 6 months for the next 4-5 years and the other hyperscalers can’t be far behind.
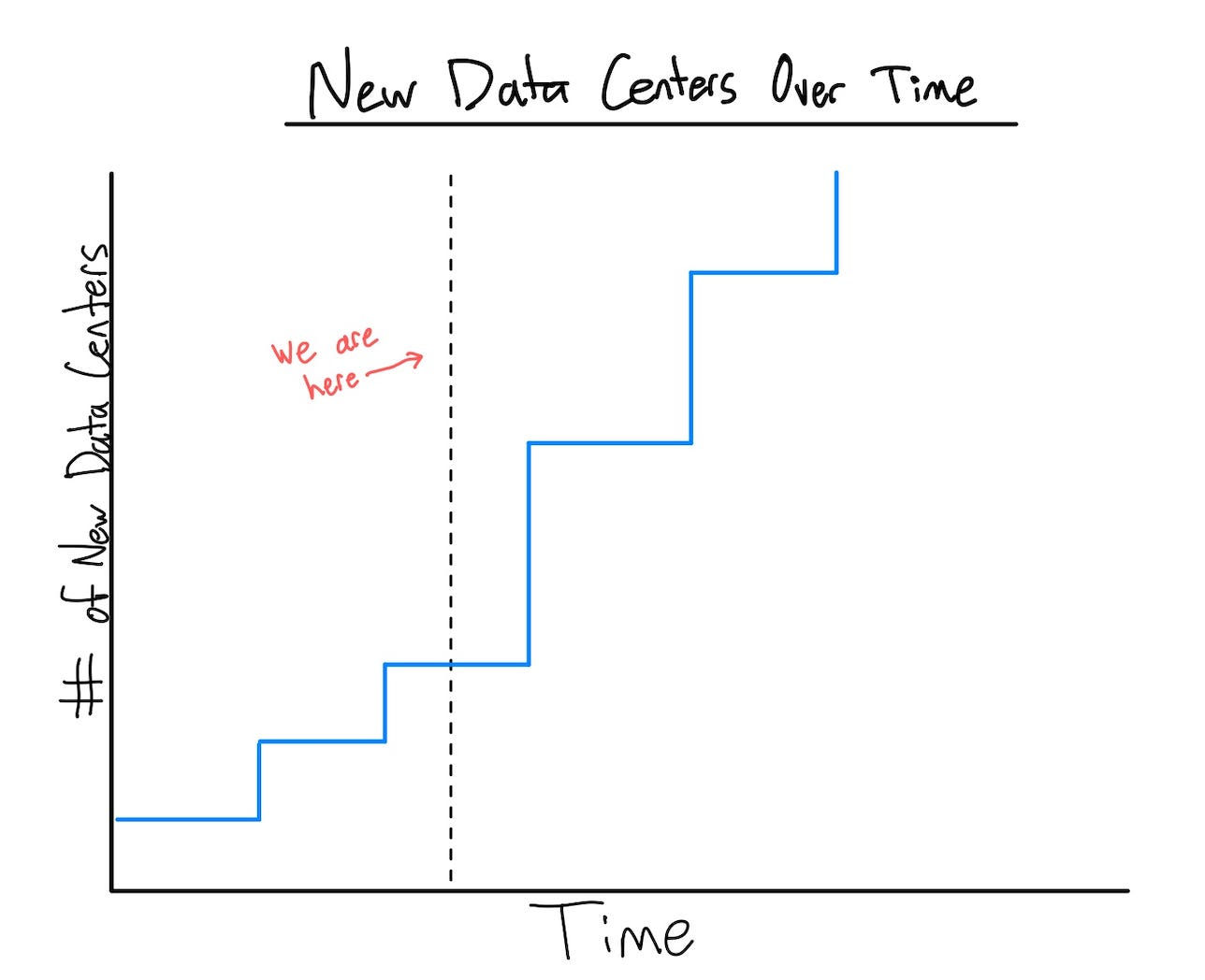
Because of how long data center construction takes, the facilities opening today were ordered years ago, before the hyperscalers launched into the arms race we see now. This means that over the next couple of years, the rate at which more data center capacity comes online will increase.
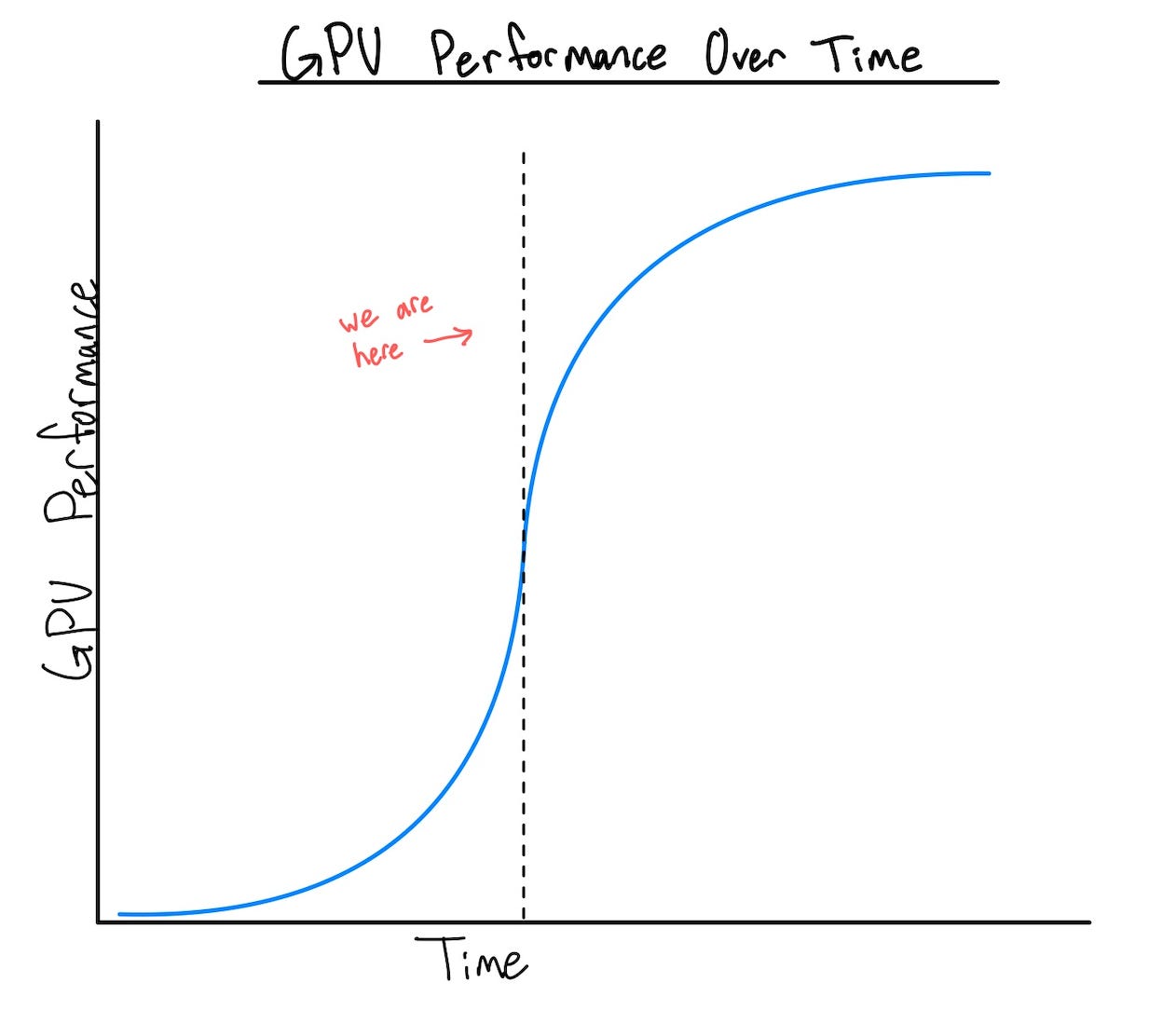
That alone would go a long way towards growing compute, but it’ll be compounded by better chips being put into the data centers. Last week’s post discussed the performance lift that each generation of chips provides and how problematic it is that Blackwell chips are sitting in inventory, rather than being deployed. That trend reverses when capacity grows. Not only will there just be more chips running compute, but the majority of compute will shift from Hopper GPUs to Blackwell and Rubin, exponentially growing compute capacity.
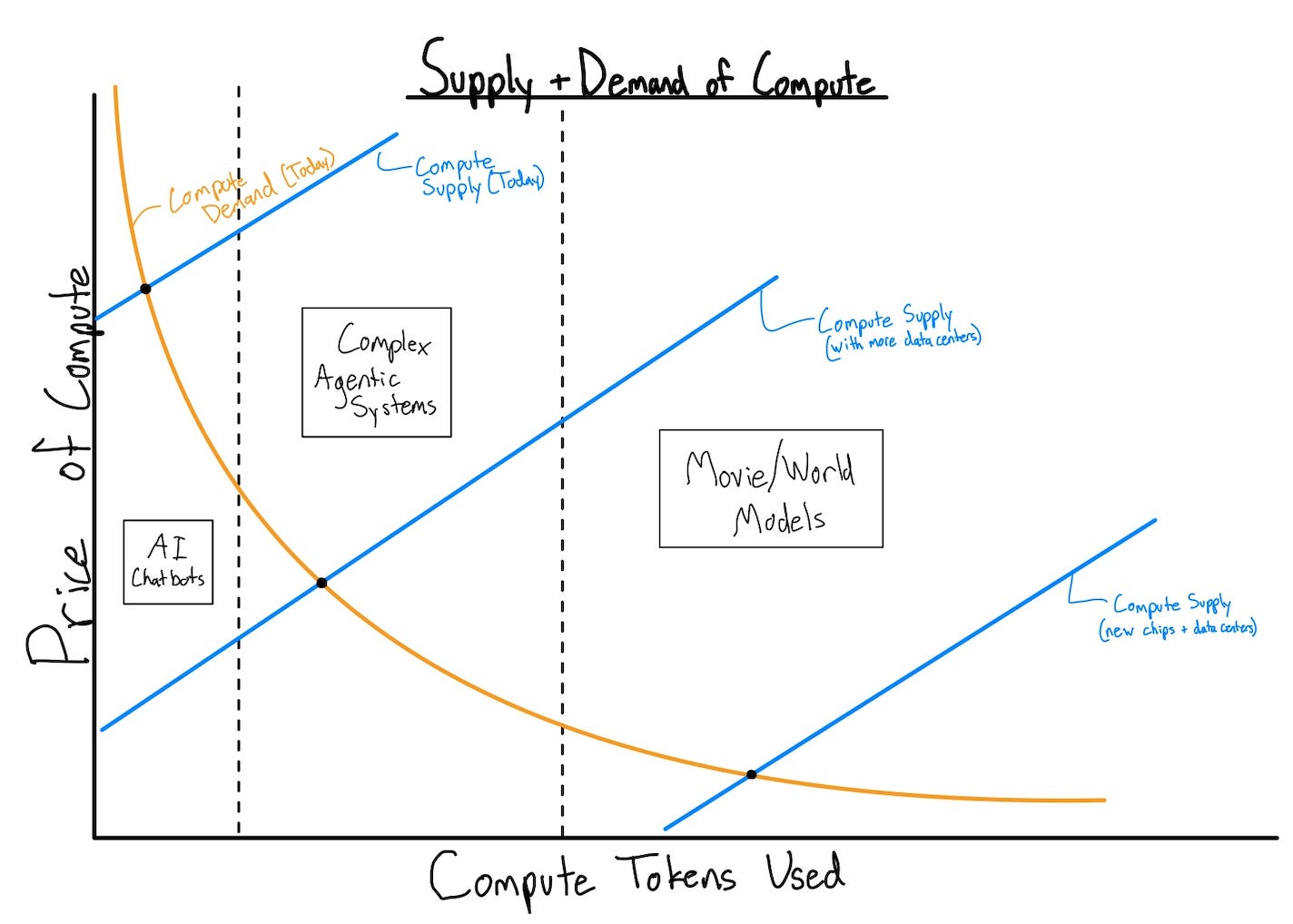
Together, these will increase the rate that the compute supply curve shifts to the right, dropping the costs and accelerating the growth in token consumption.
Compute as a Commodity
As the volume takes off and margins crater, compute will begin to look more and more commoditized.
Currently, compute isn’t differentiable between different providers. Indistinguishable products give competitive power to the consumers of compute; they can seamlessly switch to a cheaper provider. This puts significant downward pressure on its market clearing price.
I’ve been hammering this point home in recent posts, but data centers are a fixed cost industry. They require a steep upfront investment that’s paid off through high volume and thin margins over time.
The utilities buildout is another similar industry and I think looking at their buildout in the early 20th century can provide directional ideas of where data centers are headed.
In the early days, there was a hodge podge of strategies. Many factories and other large power consumers used in-house generation rather than relying on the nascent grid, meanwhile markets were littered by competing utilities racing to the bottom on pricing, limiting the scale they could achieve.
Limitations on scale ended up being a net negative for all parties involved. Utilities struggled to profitably grow, and were unable to invest in more efficient technologies. The lack of technological progress then bled through to leave businesses and consumers paying higher rates for less reliable energy.
Samuel Insull, leader of Chicago Edison, solved this by forging close relationships with the government and garnering support for geographic monopolies. Essentially, the government gave utilities the right to sole provision of power in distinct regions but gained legislative power over pricing to ensure they wouldn’t take advantage of consumers.
Because the product wasn’t differentiable, these legislative monopolies were necessary to success. Now, I don’t expect the same solution to come for data centers. Many of the hyperscalers and frontier labs have tried and failed to pursue a strategy of regulatory capture, but the solution points to the issue they’re going to need to solve.
If a legislative monopoly is off the table, hyperscalers must differentiate their products or raise switching costs high enough that going to a new provider doesn’t make economic sense.
Vertical Integration as a Moat
Steps toward this are already underway. Each of the hyperscalers are working on custom AI processing chips to replace GPUs. We previously covered the lock-in that NVIDIA has achieved by building a cohesive ecosystem through their GPUs, CUDA, and custom networking equipment. The hyperscalers will look to replace this and create their own siloed versions of the ecosystem.
With custom silicon, parallel computing/linear algebra platform, and networking equipment, they’ll build a more vertically integrated system.
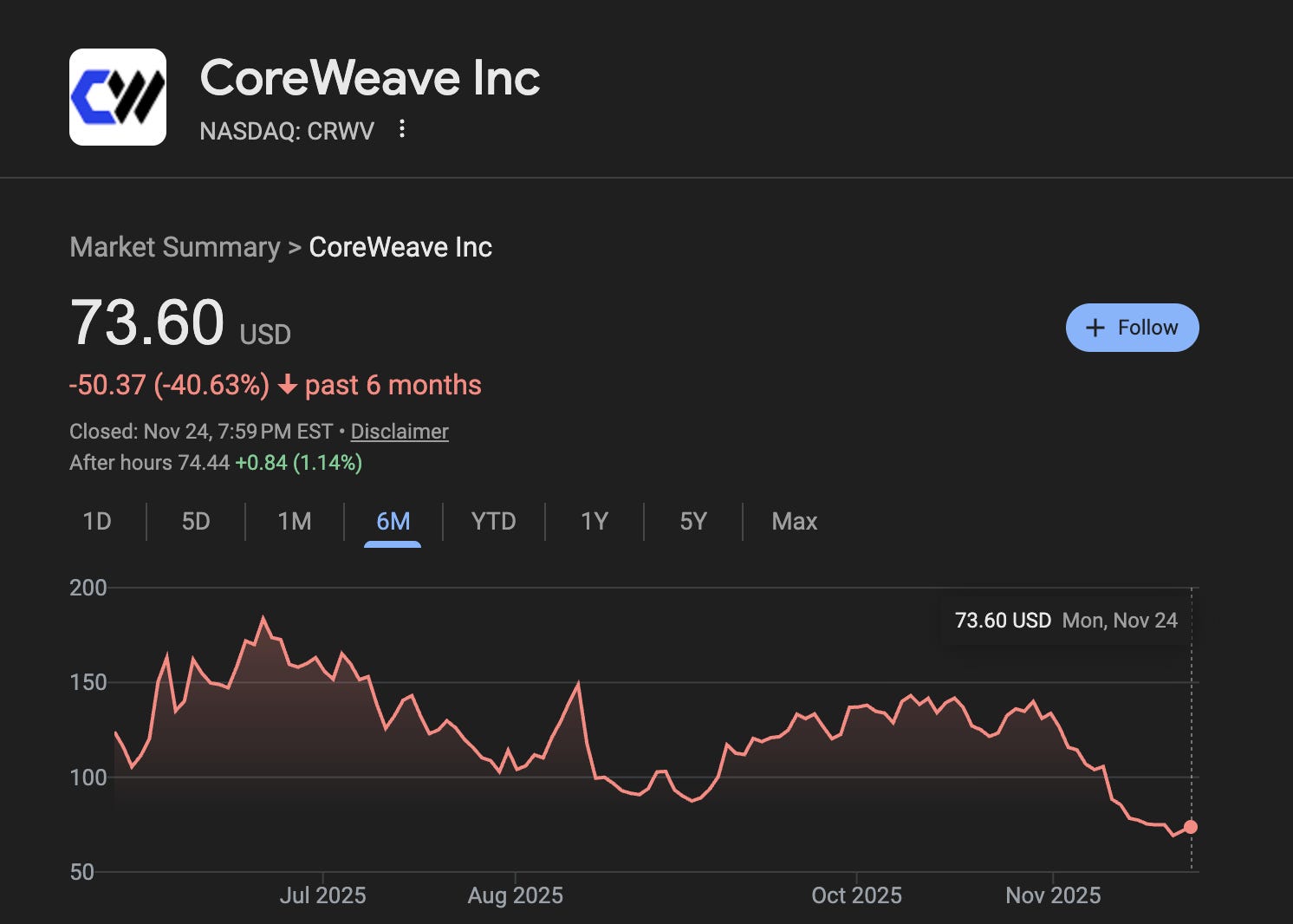
Through vertical integration, the hyperscalers should be able to shut the door on other compute providers like CoreWeave. In a world where compute is a commodity, the lowest cost producer of compute wins the market and vertical integration offers too many efficiencies for CoreWeave and other independent compute providers to keep up. Given the stock chart above, markets seem to have caught on to this and are rotating out of players like CoreWeave.
It’s not just pricing, though. At frontier labs, switching from one silicon stack to another would involve rebuilding on the new hardware from the ground up, not just a simple refactoring of the codebase. It may not permanently lock labs into a particular silicon, but developing custom chips raises the performance lift they would need to see before switching to a competitor.
Google is the most advanced in custom silicon. Just last week they released Gemini 3 and announced that no GPUs were used in its training, only their custom TPUs. Meanwhile Amazon, Microsoft, and Meta aren’t far behind, all expecting their own custom silicon to represent a growing percentage of their data centers in the future.
There’s no clear numbers on whether the transition is 2 years away, 5 years away, or something else altogether, but a shift to a world dominated by vertically integrated hyperscalers seems inevitable.
The Messy Middle
This all sounds great, but if switching between compute providers is going to be prohibitive, why’s there so much news lately about model labs doing just that?
This month alone, OpenAI inked a deal with AWS and Anthropic did the same with Microsoft, flipping their traditional alignments. I think there’s a couple driving factors behind this:
We’re in a Compute Crunch: The situation I’ve been describing in this post is about when compute become abundant. We’re not there yet. Right now, the model labs want as much compute as they can get and, since Amazon and Microsoft both still mostly run on GPUs, they can scale compute with both to address the shortage.
It’s Mutual Diversification: The model labs don’t know yet if one hyperscaler might become a breakaway leader in silicon development. Alternatively, just because Google seems to be killing it with TPUs, that’s no guarantee that all the rest of the hyperscalers will follow the same path. Some could fail. Having exposure to multiple hyperscale clouds gives labs the flexibility to pivot as they begin to get a read on development progress. On the other side, the hyperscalers believe deeply in the potential of AGI. They’ve been on record on multiple occasions stating their belief that the AI market is winner-take-all for the first one to AGI. If that’s your belief and you’re spending billions of dollars on infrastructure for AI, it would make sense to have exposure to all the labs to increase your chances of working with the winner.
Either way, in a handful of years when compute is abundant and data has come out on each hyperscalers’ silicon journey, we’ll see this hedging begin to fade.
When Intelligence Becomes Free
We’re racing ahead to a world where AI is as integrated into our lives as electricity is today. The economy may hit some bumps, or even trip and fall, along the way, but that world is becoming increasingly inevitable.
It’ll be a world where frontier models run in close alignment with vertically integrated hyperscalers. The cost to use these models will be so cheap it feels free compared to today and yet, through Jevons’ Paradox, demand will grow so much that the hyperscalers will likely look increasingly formidable.
It will be a world limited not by compute or other technical limitations, but only by what our brains can think up. Digital worlds created in seconds, innovative pharmaceutical cures to longstanding ailments, and fully autonomous robots performing arduous labor are just some examples of what’s possible when intelligence becomes free.
A quick personal note to close out the data center series:
Thank you to everyone who’s followed along over the past 3 weeks. This series has been a blast to research and write, and it’s been even more energizing seeing all the responses, texts/DMs, and new faces joining the newsletter.
A couple people have asked how they can support the project, so here’s the simple version:
Engage: Replies, comments, questions - they all help me see what’s landing and where to go next.
Share: We’re already close to 60 readers in just a couple of weeks, which is wild. As my own network starts to tap out, sharing with people who’d genuinely enjoy these posts is the most meaningful way to help this grow.
Explore and Subscribe: If this is your first time reading Uncredentialed, welcome and feel free to poke around. If you like what you see, consider subscribing!